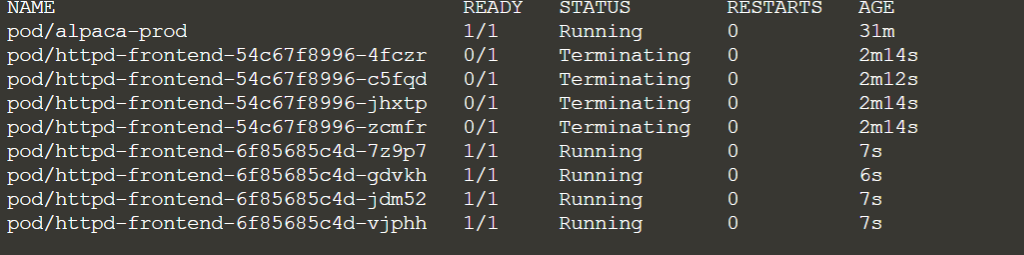
Kubernetes – Network policies
To access the pods indirectly you can use Network policies, which work like firewalls.
You can block or allow egress or ingress traffic to Pods.
The association with pods is made by using labels. They exposes HTTP and HTTPS routes,
EGRESS
If you want to restrict, for example, the outgoing TCP connections from a deployment, except a specific port (like UDP/TCP port 53 for DNS resolution), then you need to define an egress.
In the following example we also have another egress rule, that allow outgoing connection to pod having the “api” label on port 80 and 443:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: np1
namespace: venus
spec:
podSelector:
matchLabels:
id: frontend # label of the pods this policy should be applied on
policyTypes:
- Egress # we only want to control egress
egress:
- to: # 1st egress rule
- podSelector: # allow egress only to pods with api label
matchLabels:
id: api
ports:
ports:
- port: 443
- port: 80
- ports: # 2nd egress rule
- port: 53 # allow DNS UDP
protocol: UDP
- port: 53 # allow DNS TCP
protocol: TCP
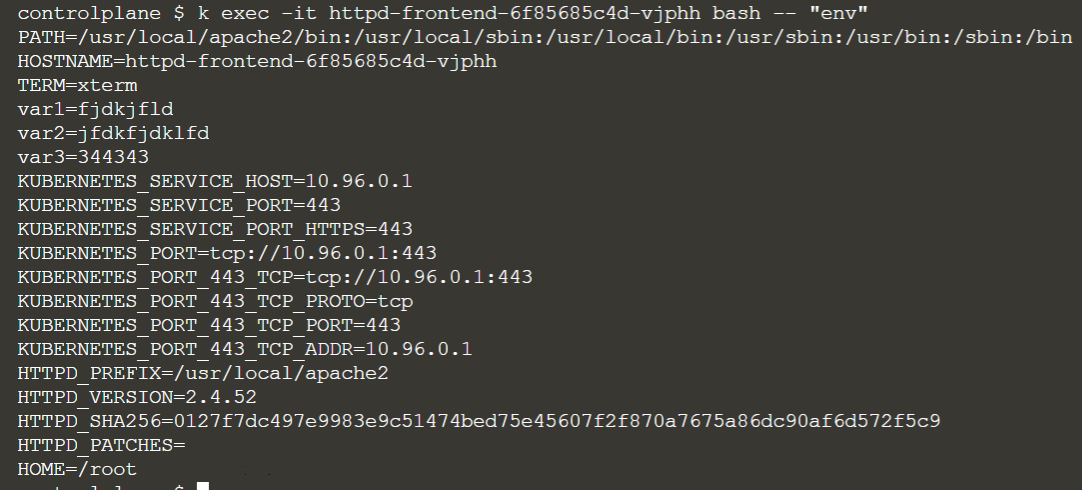
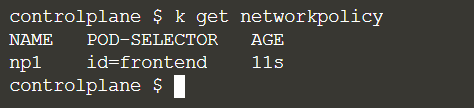
After creating the network policy, you can see that the pod selector is “frontend”
In the frontend pod you can call any website:

INGRESS
An ingress is like a virutal host and permits multiplex access to several microservices with a single load balancer. It can do load balancing itself and only works with Nodeport.
There are several ingress controllers, like nginx, Kong or Contour. You need to have one of them installed.
Let´s say we want to block traffic from FTP server, from A CIDR IP block on a certain port and from a namespace having as label “team=A”:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: untitled-policy
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
ingress:
- from:
- podSelector:
matchLabels:
app: ftp
ports:
- port: 21
- from:
- namespaceSelector:
matchLabels:
team: A
- from:
- ipBlock:
cidr: 10.2.1.3/32
ports:
- port: 443
egress:
- to:
- podSelector:
matchLabels:
app: frontend
ports:
- port: 443
- port: 80As you can see with can put several Ingress and Egress rules in the same NetworkPolicy manifest, as you have “policyTypes” in the spec.
You can create Ingresses with imperative commands too, like:
$ kubectl create ingress my-webapp-ingress --rule="foo.bar/foo=service1:8080"
The following Ingress rules are possible:
- optional host (otherwise all HTTP traffic)
- list of paths (exposed as POSIX regular expressions)
- backend (serviceName and servicePort)
You can often find a default single backend for incoming traffic that is not related to a specific path, but you can refine your backend configuration with backend types:
- simple fanout (for multiple backends, to minimize the number of load balancers)
- name based virtual hosting (to match to a specific service)
- TLS ingress (to use a TLS secret)