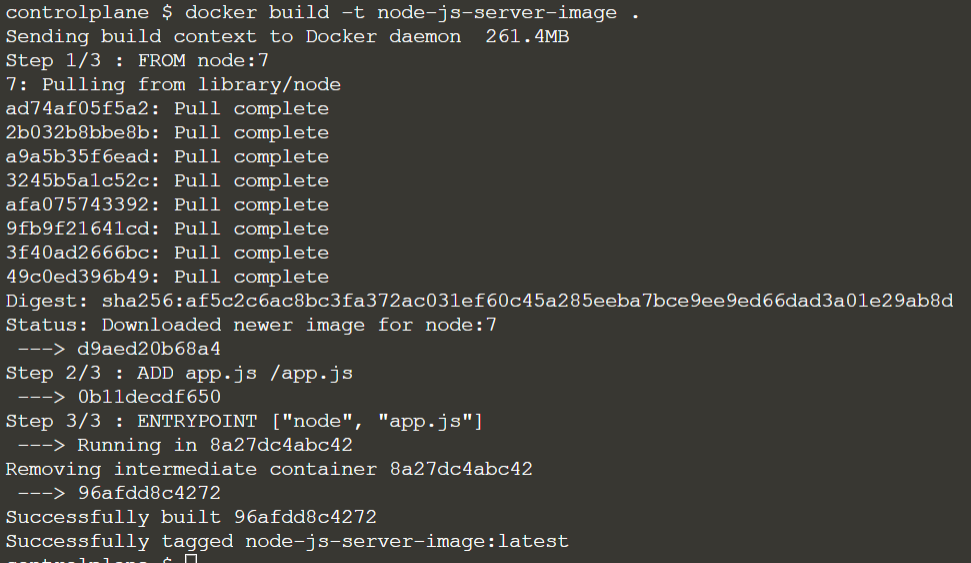
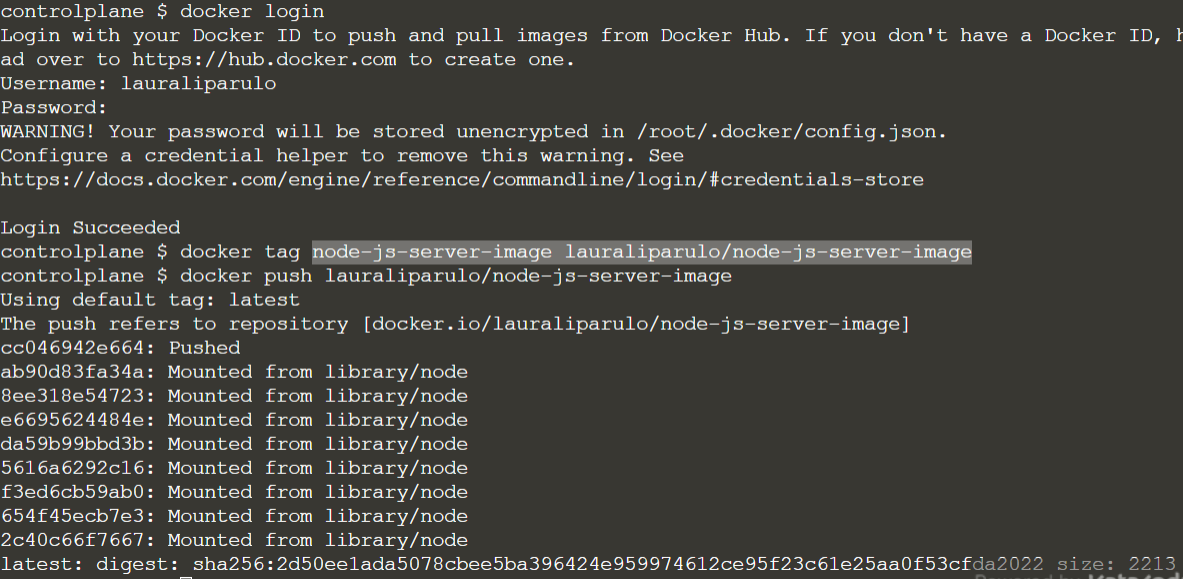
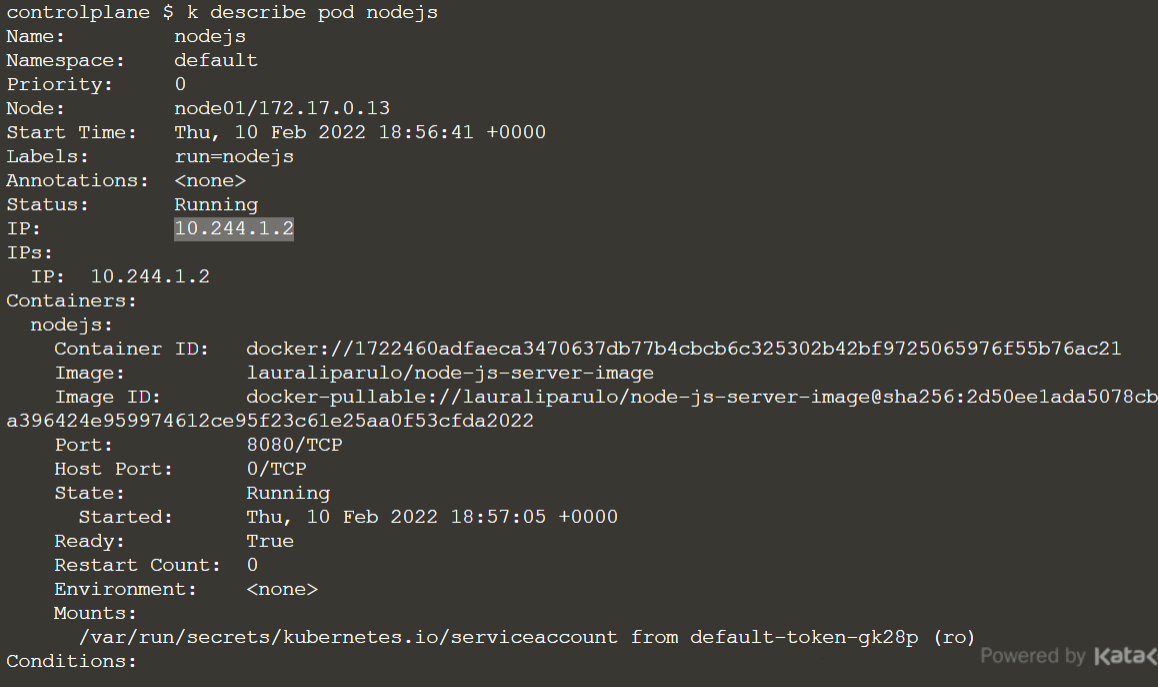
Docker commands – Getting started
To run one of the Docker official image, you can simply use “docker run”:
$ docker run centos
The first time you run it, the image can´t be found and must be downloaded:

Once downloaded, the image is saved in the docker cache and can be reused if necessary.
If it´s an official image, you would only need to enter the image name only.
But it´s taken from a user´s repo the format is: <username>/<image>.
The 100% Free software linux image Trisquel, for example, is taken from the repository of a user called “kpengboy“.
In this case, even if you are logged in, you can´t run “docker run”. You need to pull it first:
$docker pull kpengboy/trisquelbash

To see the list of the images donwload so far, run:
$ docker images
If you also want to start a bash in the container, use “-it” for the interactive mode:
$ docker run -it kpengboy/trisquel
Then you can work with the bash shell:

As default, docker will download the latest version available, but you can additionally specify a version (called “tag”) you want to work with:
$ docker run redis:4.0
If you want to access a webapp or, for example, a database, you generally get an assigned url with a port number. But you can change the ports, by adding them as parameters.
For example, if you want to run mysql and access it at a different port than 3306, use the “-p” option to give <host>:<container-port>:
$ docker run -p 52000:3307 mysqlTo persist your data, even when the container is killed, you can mount a persistent volume with “-v”:
$ docker run -v /opt/data/mysql mysql
You can pass an environment variable to you container, which might help you to avoid modifying the image and achieve some strategic solution:
$ docker run -e BACKGROUND_COLOR simple-web-app
To see which containers are running:
$ docker ps
To see the stopped containers to
$ docker ps -a
If you want to get the details of a specific container:
$ docker inspect vibrant_chatelet
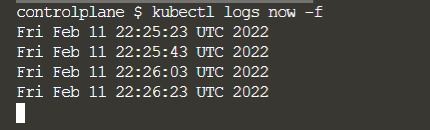
You can check the log by running:
$ docker logs vibrant_chatelet
You can start a container in background mode with the “-d” option:
$ docker -d kpengboy/trisquel

To remove a container (even if it´s running)
$ docker rm vibrant_chatelet
Or by containerID
$ docker rm 0d6d64f9053c
To remove the image you need to make sure that no container is running it first. You migh use “docker stop” or just remove it directly.
To remove an image you need:
$ docker rmi kpengboy/trisquel