Kubernetes – Getting ready for CKAD Certification
Although you can refer to the official Kubernetes during the exam, you need to be very fast at completing the tasks.
So it´s important to use aliases and shortcuts, take advantage of the documentation in the CLI (like “kubectl explain” or “–help”) and understand how to update resources.
CREATE ALIASES AND SHORTCUTS
The “k” alias for “kubectl” is provided. But to spare time, once you are logged in the exam shell, you might additionally need to define other things, like the context switching:
$ alias kn='kubectl config set-context --current --namespace
$ export now=”--force --grace-period 0”
$ export do=“--dry-run=client -o yaml”
This way, creating a yaml for a pod file becomes a lot easier:
$ k run pod1 --image=httpd:2.4.31-alpine --labels="test=true,tenancy=test" --env tempdir=/tmp $do > pod.yaml
This allows you to edit the file before creating the objects with “k create -f” or “k apply -f“:
$ k create -f pod1.yaml
USE THE CLI DOCS RATHER THAN WEB PAGES
For example $ kubectl explain pods.spec.tolerations
UPDATE DEPLOYMENTS QUICKLY
After creating a deployment with replicas:
$ kubectl create deploy httpd-frontend --image=httpd:2.4-alpine
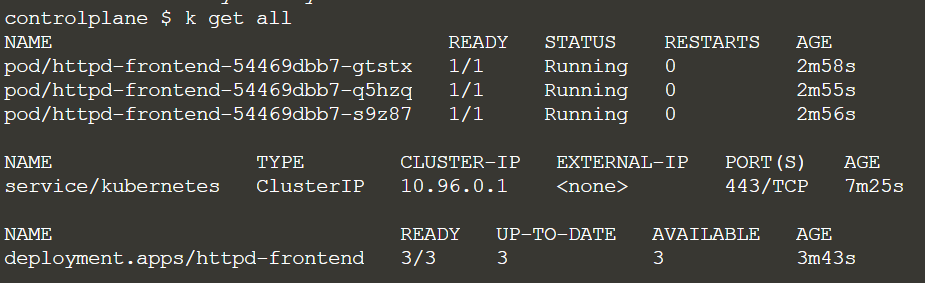
you can update the number of replica live :
$ k scale --replicas 6 deployment httpd-frontend
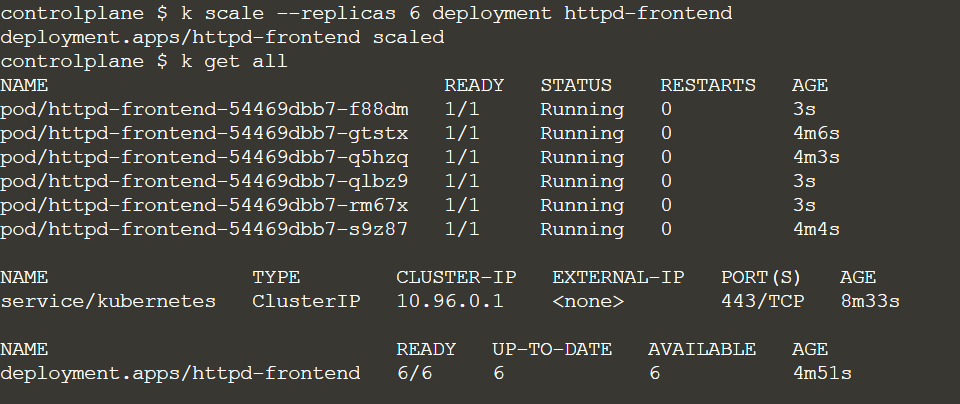
And also, for example, add resources limits:
$ k set resources deploy httpd-frontend --limits=cpu=200m,memory=512Mi --requests=cpu=100m,memory=256Mi
You can add new labels, like:
$ k label deploy httpd-frontend tenancy=prod
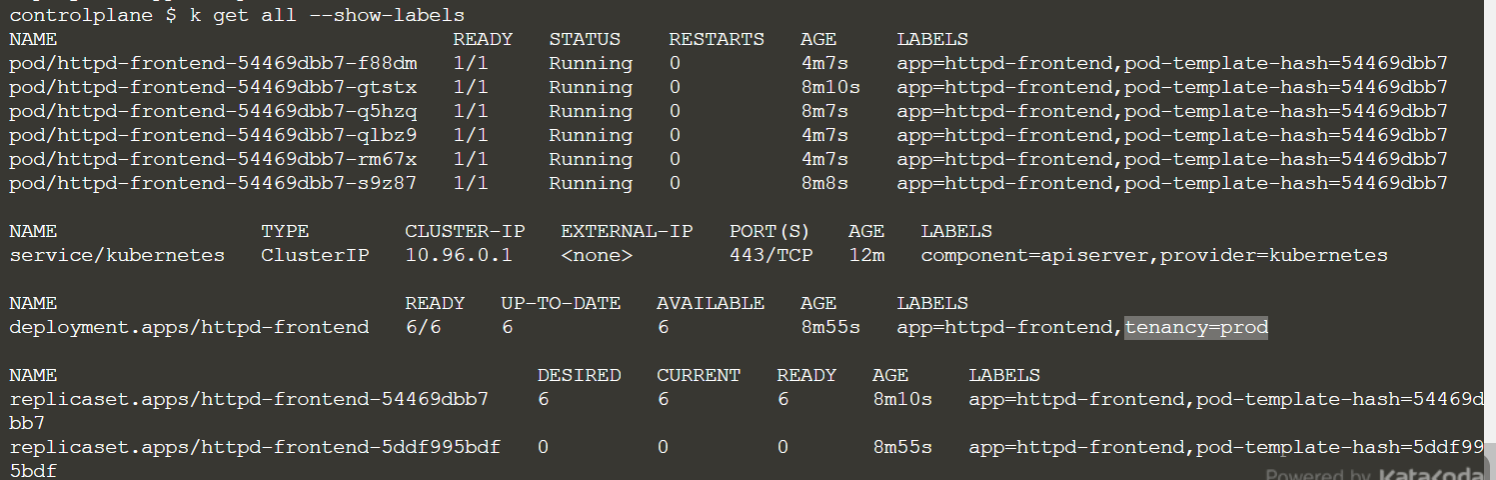
Or ovewrite an existing one:
$ k label deploy httpd-frontend app=frontend --overwrite
ADD environment variables:
$ kubectl set env deployment/registry STORAGE_DIR=/localOr even directly from a config map or a secret$ kubectl set env deployment nginx --from=configmap/vars --keys="var1,var2"
$ kubectl set env deployment nginx --from=secret/passwords --keys="pass1
Let´s try for example:
$ k set env deploy httpd-frontend --env var3=344343
Once you have set the environment variable, the pods are terminated and recreated.
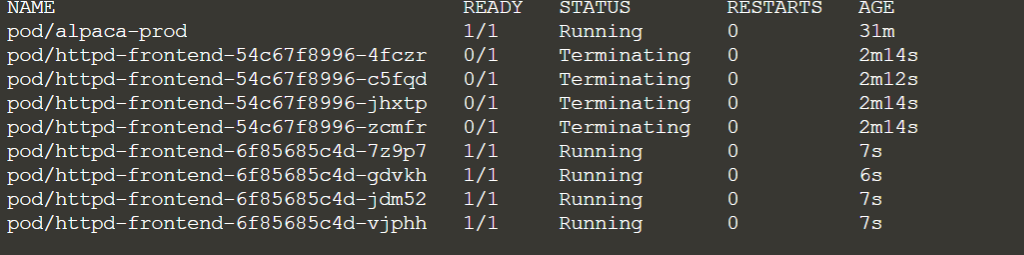
So you need to pick a new one to check if the environmente varialbe is there:
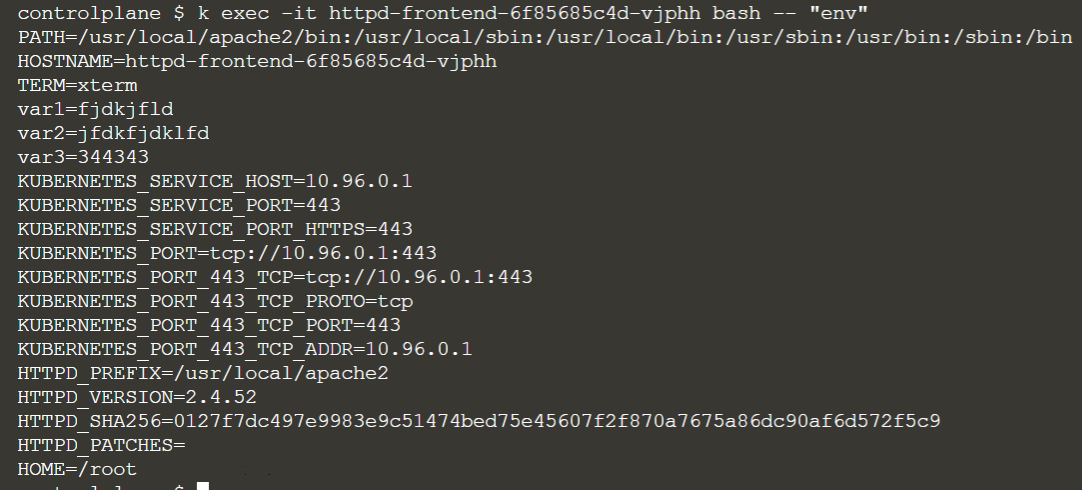
if you update the image:
$ kubectl set image deploy httpd-frontend httpd=httpd:2.6-alpine
Afterwards you can add an annotation to the current deployment, to see the information in the rollout history:
$ kubectl annotate deploy httpd-frontend kubernetes.io/change-cause='update image'

EXPOSING A DEPLOYMENT OR POD (SERVICE CREATION)
Services can also be created with commands, like:
$ kubectl expose deploy redis -n marketing --type=NodePort --port=6379 --name=msg-svc
$ kubectl expose pod redis --port=6379 --target-port=6379 --name=redis-service
this will make Kubernetes create a service for you deployment.
You can also use “create service”:
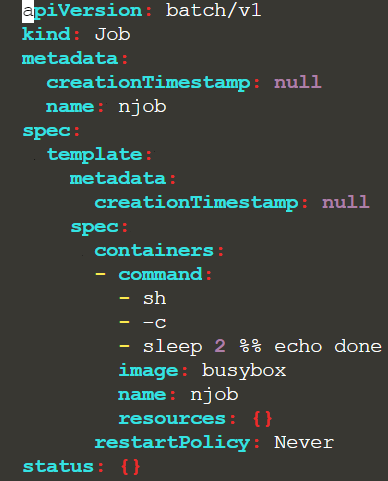
$ kubectl create service clusterip my-cs --clusterip="None"PASSING A COMMAND TO A NEW JOB
$ k create job njob –-image=busybox:1.31.0 $do > job.yaml –- sh -c “sleep 2 && echo done”
POD CPU USAGE
You will be asked to check which pods is consuming the most CPU. You can check it out with “top”:
$ k top <podname>
CREATE A VOLUME CONFIGURATION IN A POD
Although deprecated, if you only need a pod with volumes, using the “-o yaml” option will add one for you, that you can later edit.
k run nginx2 --image=nginx -o yaml > lab5.yaml
Of course there´s a lot of lines to clean up, but if you are fast with vim you can make it.
this will run a pod, but you can delete it and keep the file for creating what you need.
RUN NEW PODS WITH CONFIGURATION ELEMENTS
You add other stuff in your configuratio in the CLI directly, like:
- labels
- environment variables
- command for your pod
- service account
k run mypod --image=busybox --labels="tier=msg,review=none" --env VAR1=hello --env VAR2=world –serviceaccount=mysa -o yaml > p.yaml --command -- sh -c "while true; do date; sleep 2; done"
Then you just need to delete the pod “mypod”, edit the yaml file (deleting the “managedFields” sections) and create the pod you need.
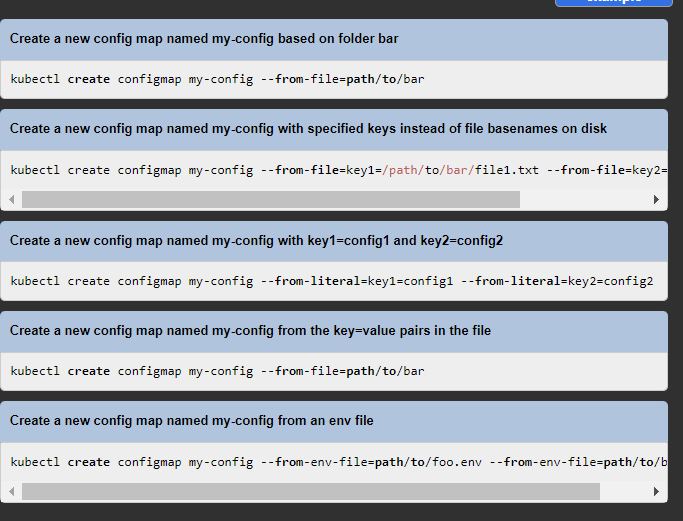
This is much better than copying and pasting codes, as you don´t have indentation issues. And you can quickly find the command options at:
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands
On the right side of the docs you always have examples:
CREATE VS RUN
You can use “kubectl run” to create pods.
$ kubectl run alpaca-prod --image=gcr.io/kuar-demo/kuard-amd64:blue --labels="ver=1,app=alpaca,env=prod"
But if you want to create a deployment you can´t use run. You will need to use “kubectl create”:
$ kubectl create deploy httpd-frontend --image=httpd:2.4-alpine
MAKE SURE THINGS WORK!
Check things are running with “kubectl get”, or describe:
$ K describe po messaging | grep -C 5 -I labels
Pipe commands with grep to avoid scrolling too much. you won´t have time!
Access pods to run commands in the bash:
$ kubectl exec -it sidecar-pod -c sidecar– /bin/sh
And curl service endpoints!
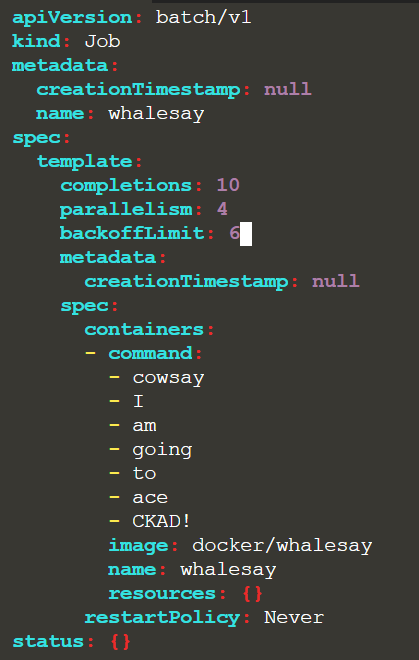
JOBS & CRONJOBS
To create a job imperatively, pass the command at the end:
$ K create job neb-new-job –-image=busybox:1.31.0 $do > /opt/course/3/job.yaml –- sh -c “sleep 2 && echo done”
To create a cronjob, you generally need to pass the schedule parameter
$ kubectl create cronjob dice –-image=kodecloud/throw dice –-schedule=”*/1 * * * *”
You can as well create a job out of a cronjob:
$ kubectl create job test-job --from=cronjob/a-cronjobTEST YOUR SERVICES
You should be able to curl your service:

A temporary pod with the nginx:alpine immage running curl would be helpful:
$ kubectl run tmp --restart=Never --rm -i --image=nginx:alpine -- curl -m 5 manager-api-svc:4444
If you can´t curl this way, probably the service is malconfigured..and endpoint missing.